Jaxon Bailey
Software Engineer in NYC

Hi, I'm Jaxon.
I'm an NYC-based software engineer and master's student at the University of Pennsylvania.
Lately I've been working on artificial intelligence, machine learning, and computer vision projects. I have experience working with Tensorflow, Keras, Pytorch, Ultralytics, and Roboflow. I'm familiar as well with Flask, Docker, Rye, Pydantic, Numpy, Pandas, OpenCV, and more. I'm most comfortable with Python, but can code in Java, C, Javascript, and Matlab as well.
I graduated from the UT Austin in 2018 with a Bachelor's in Mechanical Engineering. After graduation, I moved to Japan where I lived and worked as a teacher for 4 years. I returned to the US in 2023 to attend grad school at UPenn. Now I live in NYC and am actively seeking a job or internship as a software developer.
My favorite things are black coffee, thrift shopping, and Central Park. I love spicy foods and card games, too. I've visited 13 countries and am always looking forward to seeing someplace new. Next stops are Taipei, Yunnan, Sichuan, and Tokyo!
My projects

Built a Convolutional Neural Network (CNN) using Tensorflow/Keras to read Japanese hiragana by image recognition. Pre-processed the dataset and adjusted neural network structure and learning rate,
as well as implemented data augmentation and dropout to improve accuracy. Reached an accuracy of 83.4% and am currently
working to improve this percentage and later expand the subset of Japanese characters readable by the model.
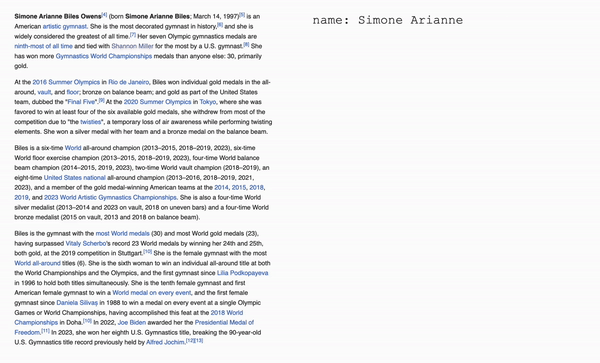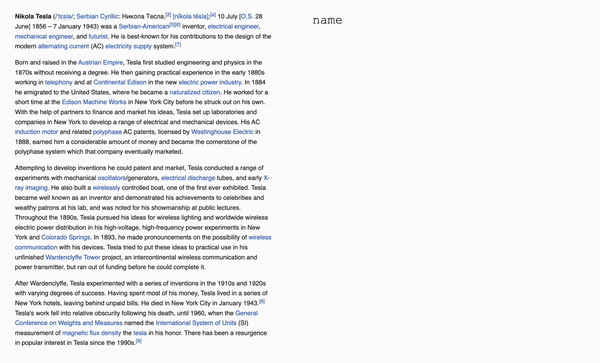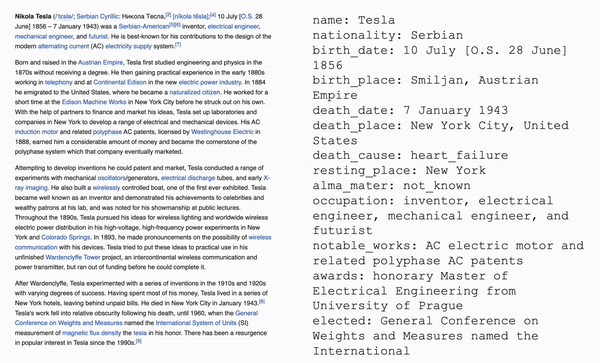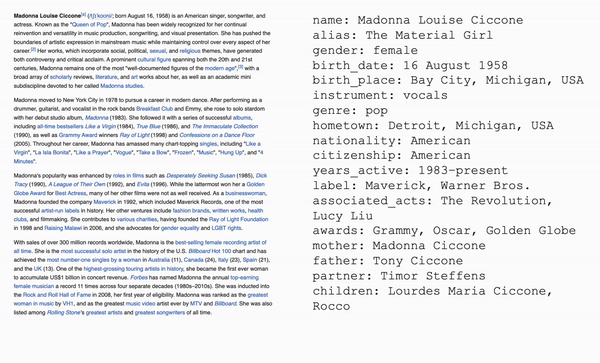
Used fine-tuning to customize an OpenAI model to parse Wikipedia biographies. The model was passed in a large JSON
file containing Wikipedia style biographies followed by parsed facts about that person in a "category: fact" format.
I adjusted the parameters of the model (temperature, top_p, frequency_penalty, presence_penalty, etc.) until the model
consistently output consistent, useful, and accurate information from the given biography.

Implemented an approximate Q-learning agent (a subclass of the grid world Q-learning agent below).
This agent navigates through a game of Pacman, learning about its environment through a series of training episodes (not shown here) to learn the optimal policy, exploiting a weighted feature function that maps features of the environment to their values from the agent's POV.
Shown here are 10 consecutive games where the agent is acting based off the optimal policy it developed in training. The agent wins every game.
This agent navigates through a game of Pacman, learning about its environment through a series of training episodes (not shown here) to learn the optimal policy, exploiting a weighted feature function that maps features of the environment to their values from the agent's POV.
Shown here are 10 consecutive games where the agent is acting based off the optimal policy it developed in training. The agent wins every game.
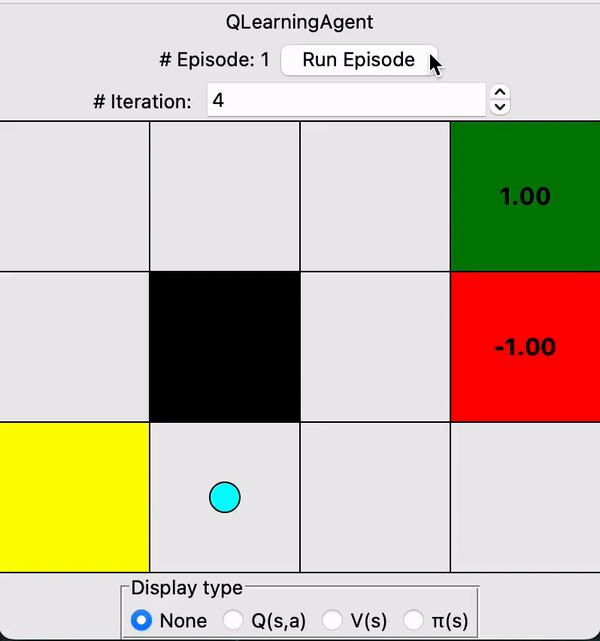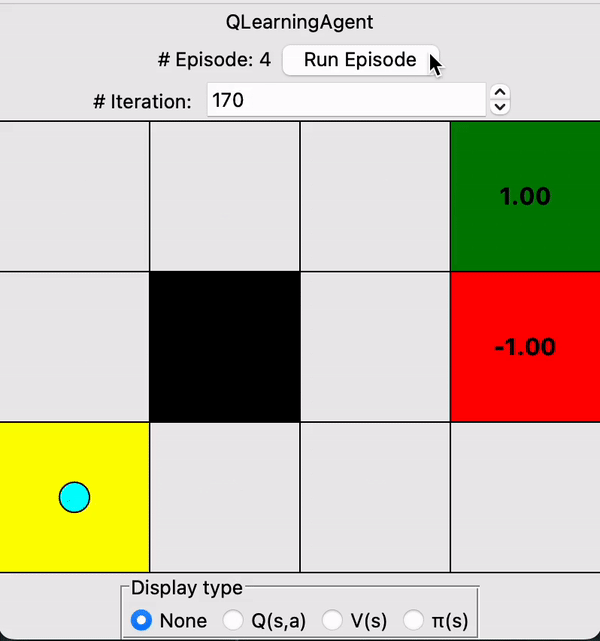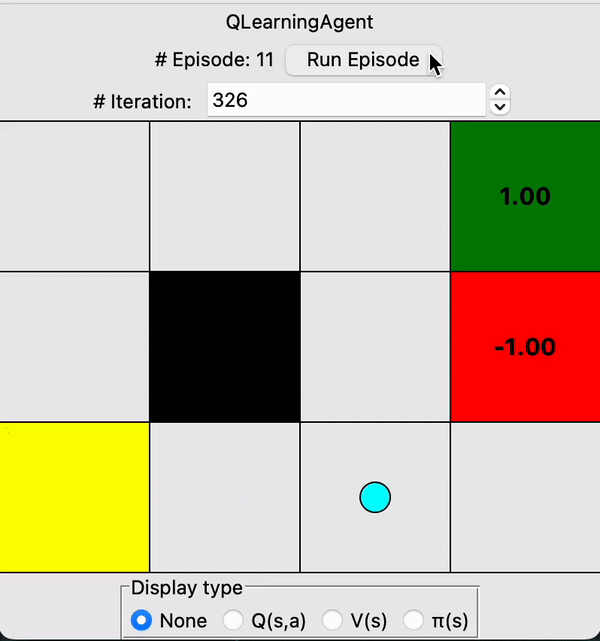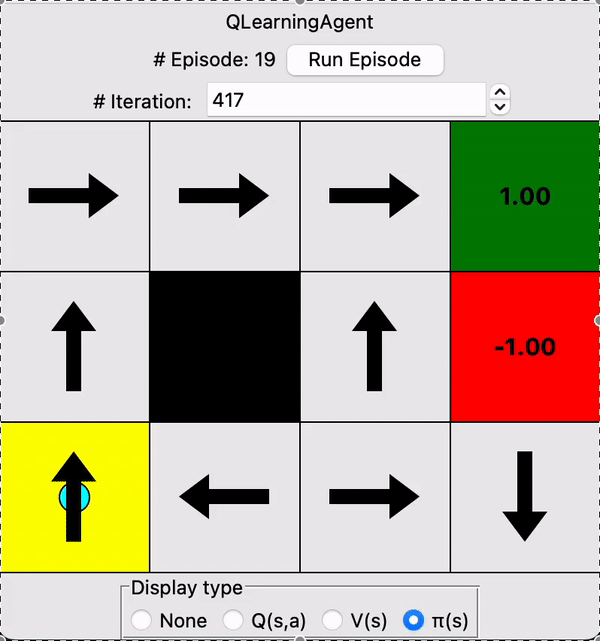
Designed a Q-learning agent that learns through interactions with its stochastic environment
via trial & error.
Note that the agent prioritizes exploration early on, then it grows more confident with increasing iterations. Through trial & error, the agent gradually begins to favor the safer upper route which completely avoids the pitfall on the lower route.
At the end of the 30s gif, you can see the values assigned by the agent to each state in the grid, as well as the optimal policy for each state denoted by the arrows.
Note that the agent prioritizes exploration early on, then it grows more confident with increasing iterations. Through trial & error, the agent gradually begins to favor the safer upper route which completely avoids the pitfall on the lower route.
At the end of the 30s gif, you can see the values assigned by the agent to each state in the grid, as well as the optimal policy for each state denoted by the arrows.

Developed an AI domino player that employs the minimax algorithm to explore the states of the game and choose
the state most likely to lead to victory. I also implemented alpha-beta pruning to more efficiently explore the game tree.
By cutting of branches of the game tree that lead to less-than-optimal outcomes for the computer, computation time is reduced
and the computer can explore deeper branches of the game, more effectively searching for the best outcome.
In this game, the human player always places dominoes vertically, while the computer places them horizontally. The last player to succesfully place a domino on the board wins. The computer considers the "best" move to be that which leaves the most available domino placements for the computer and the least available domino placements for the human opponent.
In this game, the human player always places dominoes vertically, while the computer places them horizontally. The last player to succesfully place a domino on the board wins. The computer considers the "best" move to be that which leaves the most available domino placements for the computer and the least available domino placements for the human opponent.

Implemented A* search to find the shortest path between a pair of points on a two-dimensional grid, maneuvering around obstacles.
A* relies on a heuristic function to prioritize exploration of paths that are likely to be the shortest. For this project, I used the Euclidean distance between the start and end points as the heuristic function.
A* relies on a heuristic function to prioritize exploration of paths that are likely to be the shortest. For this project, I used the Euclidean distance between the start and end points as the heuristic function.
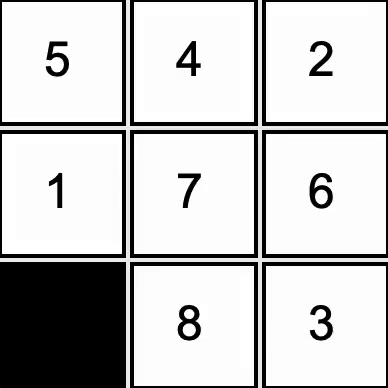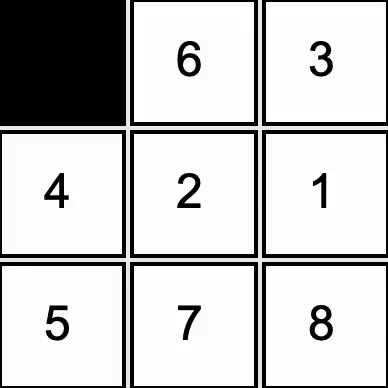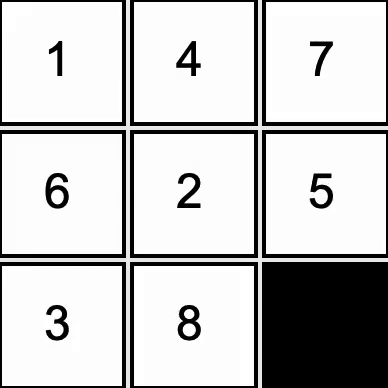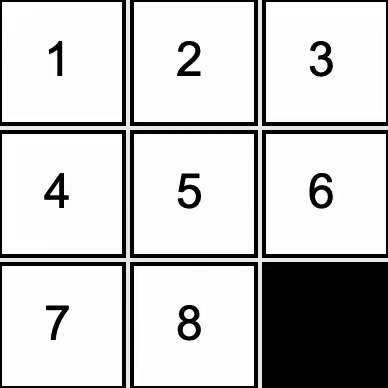
Developed a solver for the 8-tile puzzle. Implemented A* search with a Manhattan distance heuristic
to guide the AI toward a solution in a reasonable time.
The black square represents a blank space, into which the the AI can slide any of the four adjacent tiles.
The black square represents a blank space, into which the the AI can slide any of the four adjacent tiles.